目录
第一部分 概述
在数字化时代,文本数据的爆炸式增长带来了对文本相似性判断的迫切需求。无论是在内容推荐、版权保护、信息检索还是反抄袭检测等领域,准确判断文本之间的相似度都是至关重要的。传统的文本相似性判断方法,如基于词频的TF-IDF算法、余弦相似度等,虽然在某些场景下有效,但在处理大规模数据集时可能会遇到效率和精度的瓶颈。
相似度算法有很多种,可以根据不同的场景和需求选择合适的方法。一般来说,相似度算法可以分为以下几类:
- 基于距离的相似度算法:计算两个对象之间的距离来衡量它们的相似度,距离越小,相似度越高。常见的距离度量有欧几里得距离、曼哈顿距离、切比雪夫距离、明可夫斯基距离、马氏距离等。这类算法适用于数值型的数据,例如向量、矩阵等。
- 基于角度的相似度算法:计算两个对象之间的夹角来衡量它们的相似度,夹角越小,相似度越高。常见的角度度量有余弦相似度、皮尔森相关系数、斯皮尔曼相关系数、肯德尔相关系数等。这类算法适用于方向或者相关性的数据,例如文本、评分等。
- 基于集合的相似度算法:计算两个对象之间的交集和并集来衡量它们的相似度,交集越大,相似度越高。常见的集合度量有杰卡德相似系数、Dice相似系数、Simpson相似系数等。这类算法适用于分类或者布尔值的数据,例如标签、特征等。
- 基于编辑的相似度算法:计算两个对象之间的编辑操作次数来衡量它们的相似度,编辑次数越少,相似度越高。常见的编辑度量有汉明距离等。这类算法适用于字符串或者序列的数据,例如单词、DNA等。
随着AI的发展,除了上述传统相似度计算方法外,还可以依赖AI进行更加精确的语义化相似对比,在本篇文章中,综合实现的简易性以及实现成本,再对精度要求不是非常高的场景下,可以利用SimHash算法结合汉明距离计算文本间的相似性。
第二部分 算法流程
SimHash本身属于一种局部敏感hash,其主要思想是降维,将高维的特征向量转化成一个f位的指纹(fingerprint),通过算出两个指纹的汉明距离(hamming distince)来确定两篇文章的相似度,汉明距离越小,相似度越低(根据 Detecting Near-Duplicates for Web Crawling 论文中所说),一般汉明距离为3就代表两篇文章相同。
2.1 SimHash
SimHash是Google在2007年发表的论文《Detecting Near-Duplicates for Web Crawling 》中提到的一种指纹生成算法或者叫指纹提取算法,被Google广泛应用在亿级的网页去重的Job中,作为locality sensitive hash(局部敏感哈希)的一种,其主要思想是降维,什么是降维? 举个通俗点的例子,一篇若干数量的文本内容,经过simhash降维后,可能仅仅得到一个长度为32或64位的二进制由01组成的字符串,这样我们再对降维后的数据进行对比远比直接对比原文要简单,使复杂的事物,能够通过降维来简化。
2.1.1 算法步骤
SimHash算法分为5个步骤:分词、hash、加权、合并、降维,具体过程如下所述:
- 分词:给定一段语句,进行分词,得到有效的特征向量,然后为每一个特征向量设置
1-5等5个级别的权重(如果是给定一个文本,那么特征向量可以是文本中的词,其权重可以是这个词出现的次数)。例如给定一段语句:“我是蒋固金”,分词后为:我、是、蒋固金,然后为每个特征向量赋予权值:我(4)、是(1)、蒋固金(5),其中括号里的数字代表这个单词在整条语句中的重要程度,数字越大代表越重要。 - hash:通过hash函数计算各个特征向量的hash值,hash值为二进制数
01组成的n-bit签名。比如我的hash值Hash(我)为100101,蒋固金的hash值Hash(蒋固金)为101011。就这样,字符串就变成了一系列数字。 - 加权:在hash值的基础上,给所有特征向量进行加权,即
W = Hash * weight,且遇到1则hash值和权值正相乘,遇到0则hash值和权值负相乘。例如给我的hash值100101加权得到:W(我) = 100101 * 4 = 4 -4 -4 4 -4,给蒋固金的hash值101011加权得到:W(蒋固金) = 101011 * 5 = 5 -5 5 -5 5,其余特征向量类似此般操作。 - 合并:将上述各个特征向量的加权结果累加,变成只有一个序列串。拿前两个特征向量举例,例如
我的4 -4 -4 4 -4和蒋固金的5 -5 5 -5 5进行累加,得到4+5 -4+-5 -4+5 4+-5 -4+5,得到9 -9 1 -1 1。 - 降维:对于
n-bit签名的累加结果,如果大于0则置1,否则置0,从而得到该语句的simhash值,最后我们便可以根据不同语句simhash的汉明距离来判断它们的相似度。例如把上面计算出来的9 -9 1 -1 1降维(某位大于0记为1,小于0记为0),得到的01串为:1 0 1 0 1,从而形成它们的simhash签名。
2.1.2 特征字节的生成
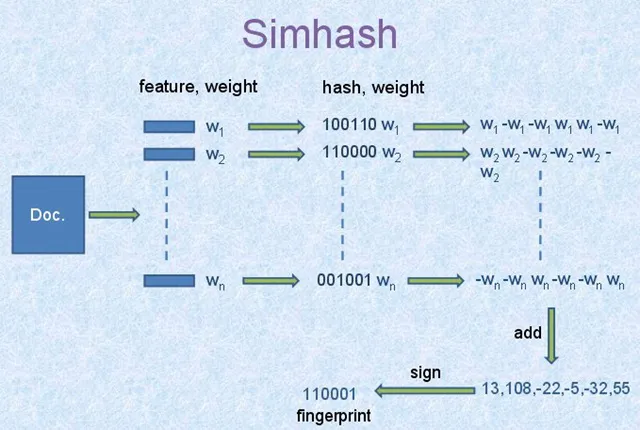
- 选择simhash的位数,例如
32位或64位。 - 将Doc文件进行分词,并赋予权重,赋予权重的方法有很多种,可以根据词频等信息的一些方法。将每个关键词转换为对应位数的哈希码,在这里,我们假设我们的哈希位数为
6,那么依据图中信息可知n个词的哈希码如上面100110、110000。 - 然后对这
n个哈希码按列相加,如果哈希码为1,那么+weight,反之-weight,计算最后生成的结果,如上图所示的[13,108,-22,-5,-32,55]。 - 然后由
[13,108,-22,-5,-32,55]转换成最终的哈希码[1,1,0,0,0,1],正取1,负取0。
2.2 汉明距离(海明距离)
汉明距离(Hamming Distance)是一种用于衡量两个等长字符串之间差异的度量方式。它定义为在相同位置上不同的字符个数,即两个字符串对应位置字符不同的位数总和。
- 概念解释:汉明距离的计算方法很简单,它从两个字符串的第一个字符开始,依次比较每个位置上的字符是否相同。如果相同,则距离不增加;如果不同,则距离增加1。汉明距离的值越小,说明两个字符串越相似;值越大,说明它们差异越大。
- 使用场景:
- 错误检测和校正:在数据传输或存储中,用汉明距离来检测和纠正错误。例如,通过比较发送和接收到的数据位来检测通信中的错误。
- 相似性匹配:在文本或图像处理中,汉明距离可以用于比较两个样本的相似度。较小的汉明距离通常表示两者的内容较为接近。
- 密码学应用:在密码学中,汉明距离被用来衡量两个密钥的不同之处,以评估其安全性和唯一性。
第四部分 实现步骤
4.1 分词
在Java中,HanLP、Jieba和IK分词器都是常用的中文分词工具,各自有其特点和优缺点。
HanLP
HanLP(Han Language Processing)是一款面向中文文本处理的自然语言处理工具包,由一系列模型和算法组成,包括分词、词性标注、命名实体识别等功能。
-
特性:
- 提供了多种分词算法和模型,包括基于深度学习的算法和传统的规则算法。
- 支持自定义词典和用户词性标注。
- 支持多种中文文本处理任务,如命名实体识别、关键词提取等。
-
优点:
- 准确度高,支持多种领域的中文文本处理。
- 功能丰富,覆盖了除分词外的其他自然语言处理任务。
- 社区活跃,有较好的更新和维护。
-
缺点:
- 需要较大的内存和计算资源,特别是在使用深度学习模型时。
- 部分功能较复杂,对初学者不够友好。
Jieba
Jieba分词是一个Python实现的中文分词工具,由于其成熟和广泛应用,也有Java的实现版本。
-
特性:
- 支持基于统计和规则的分词算法。
- 提供了简单易用的接口和自定义词典功能。
- 在中文分词的速度和准确度上有较好的平衡。
-
优点:
- 性能稳定,经过长期的优化和使用。
- 简单易用,适合快速集成和使用。
-
缺点:
- 由于是
Python的原生实现,Java版本可能在性能和功能上略有差距。 - 对于特定领域的文本处理可能需要额外的定制和优化。
- 由于是
IK分词器
IK分词器是一个开源的中文分词工具,主要用于Java平台。
-
特性:
- 支持细粒度和智能分词模式,可根据不同需求选择。
- 提供了用户词典的支持,可以进行动态加载和更新。
- 适合处理各种文本类型,包括较长的文本段落。
-
优点:
- 稳定性高,经过长期的使用和优化。
- 支持的分词模式和词典管理比较灵活。
-
缺点:
- 分词准确度一般,可能在某些特定场景下表现不佳。
- 社区支持相对较小,更新和维护较为有限。
如果追求高准确度和多功能支持,HanLP是一个不错的选择;如果对性能要求较高且需要简单易用的分词工具,可以考虑Jieba或IK分词器。在本节中将使用HanLP实现文本的分词。
为了降低无关数据对分词结果的影响,在进行分词前可以对文本进行预处理,过滤一些特殊字符,示例代码如下:
java/**
* 过滤特殊字符
*/
public static String clearSpecialCharacters(String content) {
// 将内容转换为小写
content = StringUtils.lowerCase(content);
// 过滤特殊字符
String[] strings = { " ", "\n", "\r", "\t", "\\r", "\\n", "\\t",
" ", "&", "<", ">", """, "&qpos;", " " };
for (String string : strings) {
content = content.replaceAll(string, "");
}
return content;
}
增加HanLP依赖包
xml<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>portable-1.8.4</version>
</dependency>
分词的策略在使用中可能发产生变化,可以将分词的逻辑抽象为一个接口以便于后续替换分词的实现。
javaimport java.util.function.BiConsumer;
/**
* 分词器
*/
public interface Tokenizer {
/**
* 分段
*
* @param content 内容
* @param consumer 分词 词性
*/
void segment(String content, BiConsumer<String, String> consumer);
}
根据定义的接口,完成HanLP分词的实现。
javaimport com.hankcs.hanlp.seg.common.Term;
import com.hankcs.hanlp.tokenizer.StandardTokenizer;
import java.util.List;
import java.util.function.BiConsumer;
/**
* Hanlp分词器
*/
public class HanlpTokenizer implements Tokenizer {
@Override
public void segment(String content, BiConsumer<String, String> consumer) {
// 对内容进行分词处理
List<Term> terms = StandardTokenizer.segment(content);
for (Term term : terms) {
// 获取分词字符串
String word = term.word;
// 获取分词词性
String nature = term.nature.toString();
consumer.accept(word, nature);
}
}
}
4.2 计算分词Hash值
不同的Hash计算策略最终得到的结果也会不同,与分词逻辑一样,也可以将计算分词Hash值的逻辑抽象为接口。
java/**
* 分词Hash策略
*/
public interface WordHashStrategy {
/**
* 获取分词Hash
*
* @param word 分词
* @param nature 词性
* @param hashCount hash数量
*/
BigInteger getWordHash(String word, String nature, int hashCount);
}
接下来提供一种计算分词Hash值的实现示例
javaimport org.apache.commons.lang3.StringUtils;
import java.math.BigInteger;
/**
* 默认分词Hash策略
*/
public class DefaultWordHashStrategy implements WordHashStrategy {
/**
* 分词最小长度限制
*/
private static final int WORD_MIN_LENGTH = 3;
private static final BigInteger ILLEGAL_X = new BigInteger("-1");
private static final BigInteger BIGINT_2 = new BigInteger("2");
private static final BigInteger BIGINT_1000003 = new BigInteger("1000003");
private static final BigInteger BIGINT_NEGATIVE_2 = new BigInteger("-2");
private final int wordMinLength;
public DefaultWordHashStrategy() {
this(WORD_MIN_LENGTH);
}
public DefaultWordHashStrategy(int wordMinLength) {
this.wordMinLength = wordMinLength;
}
@Override
public BigInteger getWordHash(String word, String nature, int hashCount) {
if (StringUtils.isBlank(word)) {
// 如果分词为null,则默认hash为0
return BigInteger.ZERO;
}
// 分词补位,如果过短会导致Hash算法失败
while (word.length() < this.wordMinLength) {
word = word + word.charAt(0);
}
// 分词位运算
char[] wordArray = word.toCharArray();
BigInteger hash = BigInteger.valueOf(wordArray[0] << 7);
// 初始桶pow运算
BigInteger mask = BIGINT_2.pow(hashCount).subtract(BigInteger.ONE);
for (char item : wordArray) {
BigInteger temp = BigInteger.valueOf(item);
hash = hash.multiply(BIGINT_1000003).xor(temp).and(mask);
}
hash = hash.xor(new BigInteger(String.valueOf(word.length())));
if (hash.equals(ILLEGAL_X)) {
hash = BIGINT_NEGATIVE_2;
}
return hash;
}
}
4.3 计算文章指纹
java/**
* 使用SimHash算法生成文本的指纹信息
*
* @param content 文本内容
*/
public BigInteger simHash(String content) {
int[] hashArray = new int[this.hashCount];
// 设置分词统计量
Map<String, Integer> wordMap = new HashMap<>();
// 对内容进行分词处理
this.tokenizer.segment(content, (word, nature) -> {
// 过滤停用词
if (this.stopWordStrategy.isStopWord(word, nature)) {
return;
}
// 过滤超频词
if (wordMap.containsKey(word)) {
Integer count = wordMap.get(word);
if (count > this.wordOverCount) {
return;
}
wordMap.put(word, count + 1);
} else {
wordMap.put(word, 1);
}
// 计算单个分词的Hash值
BigInteger wordHash = this.wordHashStrategy.getWordHash(word, nature, this.hashCount);
// 设置初始权重
int weight = this.wordWeightStrategy.getWordWeight(word, nature);
for (int i = 0; i < this.hashCount; i++) {
// 向量位移
BigInteger bitMask = BigInteger.ONE.shiftLeft(i);
// 计算所有分词的向量
if (wordHash.and(bitMask).signum() != 0) {
hashArray[i] += weight;
} else {
hashArray[i] -= weight;
}
}
});
// 生成指纹,降维处理
BigInteger fingerprint = BigInteger.ZERO;
for (int i = 0; i < this.hashCount; i++) {
if (hashArray[i] >= 0) {
fingerprint = fingerprint.add(BigInteger.ONE.shiftLeft(i));
}
}
return fingerprint;
}
计算文章指纹除了上述步骤的分词与计算分词Hash值外,对分词后的数据还可以进行一些额外的处理,比如忽略一些语义上没什么意义的分词、出现频率过高的分词,针对不同的分词设置不同的权重等等。上述示例代码中已添加了相关处理逻辑,涉及到的辅助接口与实现可参考本节后续示例代码。
停用词策略
- 停用词策略接口
java/**
* 停用词策略
*/
public interface StopWordStrategy {
/**
* 是否停用词
*
* @param word 分词
* @param nature 词性
*/
boolean isStopWord(String word, String nature);
}
Hanlp停用词策略实现
javaimport com.hankcs.hanlp.corpus.tag.Nature;
import java.util.HashSet;
import java.util.Set;
/**
* Hanlp停用词策略
*/
public class HanlpStopWordStrategy implements StopWordStrategy {
private final Set<String> stopWordSet;
public HanlpStopWordStrategy() {
Nature[] stopNatures = {
// 去除标点符号
Nature.w, Nature.wd, Nature.wf, Nature.wj, Nature.wky, Nature.wkz,
Nature.wm, Nature.wn, Nature.wp, Nature.ws, Nature.wt, Nature.ww,
Nature.wyy, Nature.wyz,
// 去除助词
Nature.u, Nature.uzhe, Nature.ule, Nature.uguo, Nature.ude1,
Nature.ude2, Nature.ude3, Nature.usuo, Nature.udeng, Nature.uyy,
Nature.udh, Nature.uls, Nature.uzhi, Nature.ulian };
this.stopWordSet = new HashSet<>((int) (stopNatures.length / 0.75 + 1));
for (Nature nature : stopNatures) {
this.stopWordSet.add(nature.toString());
}
}
@Override
public boolean isStopWord(String word, String nature) {
// 过滤停用词性
return this.stopWordSet.contains(nature);
}
}
分词权重策略
- 分词权重策略接口
java/**
* 分词权重策略
*/
public interface WordWeightStrategy {
/**
* 获得分词权重
*
* @param word 分词
* @param nature 词性
*/
int getWordWeight(String word, String nature);
}
- 固定分词权重策略实现
java/**
* 固定分词权重策略
*/
public class FixedWordWeightStrategy implements WordWeightStrategy {
private final int wordWeight;
/**
* 默认固定分词权重1
*/
public FixedWordWeightStrategy() {
this(1);
}
public FixedWordWeightStrategy(int wordWeight) {
this.wordWeight = wordWeight;
}
@Override
public int getWordWeight(String word, String nature) {
return this.wordWeight;
}
}
4.4 计算相似度
java/**
* 获取相似度
*/
public double getSimilar(BigInteger one, BigInteger two) {
// 获取海明距离
double hammingDistance = this.getHammingDistance(one, two);
// 求得海明距离百分比
double scale = (1 - hammingDistance / this.hashCount) * 100;
return Double.parseDouble(String.format("%.2f", scale));
}
/**
* 获取海明距离
*/
public int getHammingDistance(BigInteger hash1, BigInteger hash2) {
// 求差集
BigInteger subtract = BigInteger.ONE.shiftLeft(this.hashCount).subtract(BigInteger.ONE);
// 求异或
BigInteger xor = hash1.xor(hash2).and(subtract);
int distance = 0;
while (xor.signum() != 0) {
distance += 1;
xor = xor.and(xor.subtract(BigInteger.ONE));
}
return distance;
}
4.5 测试
java@Test
public void testSimHash() throws Exception {
List<String> list = new ArrayList<>();
list.add(SimHash.clearSpecialCharacters("我是蒋固金,欢迎查看我的博客"));
list.add(SimHash.clearSpecialCharacters("我是蒋固金,欢迎查看我的博"));
list.add(SimHash.clearSpecialCharacters("欢迎查看我的博客"));
list.add(SimHash.clearSpecialCharacters("我是蒋固金"));
list.add(SimHash.clearSpecialCharacters("我是"));
String original = SimHash.clearSpecialCharacters("我是蒋固金,欢迎查看我的博客");
SimHash simHash = new SimHash();
BigInteger originalSimHash = simHash.simHash(original);
// 计算相似度
for (int i = 0; i < list.size(); i++) {
BigInteger hash = simHash.simHash(list.get(i));
int distance = simHash.getHammingDistance(originalSimHash, hash);
double similar = simHash.getSimilar(originalSimHash, hash);
System.out.println("索引:" + i + ", 汉明距离:" + distance
+ ", 相似度:" + similar);
}
}
测试结果如下:
索引:0, 汉明距离:0, 相似度:100.0 索引:1, 汉明距离:8, 相似度:87.5 索引:2, 汉明距离:13, 相似度:79.69 索引:3, 汉明距离:18, 相似度:71.88 索引:4, 汉明距离:19, 相似度:70.31
上述示例仅为演示实现流程,实际使用时需要根据业务场景设置合适的参数以增加检测的准确度。
SimHash完整代码如下:
javaimport org.apache.commons.lang3.StringUtils;
import java.math.BigInteger;
import java.util.HashMap;
import java.util.Map;
public class SimHash {
/**
* 默认Hash数量
*/
private static final int DEFAULT_HASH_COUNT = 64;
/**
* 超频词最大上限
*/
private static final int WORD_OVER_COUNT = 5;
private final int hashCount;
private final int wordOverCount;
private final WordWeightStrategy wordWeightStrategy;
private final StopWordStrategy stopWordStrategy;
private final WordHashStrategy wordHashStrategy;
private final Tokenizer tokenizer;
public SimHash() {
this(DEFAULT_HASH_COUNT, WORD_OVER_COUNT, new FixedWordWeightStrategy(),
new HanlpStopWordStrategy(), new DefaultWordHashStrategy(),
new HanlpTokenizer());
}
public SimHash(int hashCount, int wordOverCount,
WordWeightStrategy wordWeightStrategy, StopWordStrategy stopWordStrategy,
WordHashStrategy wordHashStrategy, Tokenizer tokenizer) {
this.hashCount = hashCount;
this.wordOverCount = wordOverCount;
this.wordWeightStrategy = wordWeightStrategy;
this.stopWordStrategy = stopWordStrategy;
this.wordHashStrategy = wordHashStrategy;
this.tokenizer = tokenizer;
}
/**
* 使用SimHash算法生成文本的指纹信息
*
* @param content 文本内容
*/
public BigInteger simHash(String content) {
int[] hashArray = new int[this.hashCount];
// 设置分词统计量
Map<String, Integer> wordMap = new HashMap<>();
// 对内容进行分词处理
this.tokenizer.segment(content, (word, nature) -> {
// 过滤停用词
if (this.stopWordStrategy.isStopWord(word, nature)) {
return;
}
// 过滤超频词
if (wordMap.containsKey(word)) {
Integer count = wordMap.get(word);
if (count > this.wordOverCount) {
return;
}
wordMap.put(word, count + 1);
} else {
wordMap.put(word, 1);
}
// 计算单个分词的Hash值
BigInteger wordHash = this.wordHashStrategy.getWordHash(word, nature, this.hashCount);
// 设置初始权重
int weight = this.wordWeightStrategy.getWordWeight(word, nature);
for (int i = 0; i < this.hashCount; i++) {
// 向量位移
BigInteger bitMask = BigInteger.ONE.shiftLeft(i);
// 计算所有分词的向量
if (wordHash.and(bitMask).signum() != 0) {
hashArray[i] += weight;
} else {
hashArray[i] -= weight;
}
}
});
// 生成指纹,降维处理
BigInteger fingerprint = BigInteger.ZERO;
for (int i = 0; i < this.hashCount; i++) {
if (hashArray[i] >= 0) {
fingerprint = fingerprint.add(BigInteger.ONE.shiftLeft(i));
}
}
return fingerprint;
}
/**
* 过滤特殊字符
*/
public static String clearSpecialCharacters(String content) {
// 将内容转换为小写
content = StringUtils.lowerCase(content);
// 过滤特殊字符
String[] strings = { " ", "\n", "\r", "\t", "\\r", "\\n", "\\t",
" ", "&", "<", ">", """, "&qpos;", " " };
for (String string : strings) {
content = content.replaceAll(string, "");
}
return content;
}
/**
* 获取相似度
*/
public double getSimilar(BigInteger one, BigInteger two) {
// 获取海明距离
double hammingDistance = this.getHammingDistance(one, two);
// 求得海明距离百分比
double scale = (1 - hammingDistance / this.hashCount) * 100;
return Double.parseDouble(String.format("%.2f", scale));
}
/**
* 获取相似度
*/
public double getSimilar(long hash1, long hash2) {
// 获取海明距离
double hammingDistance = this.getHammingDistance(hash1, hash2);
// 求得海明距离百分比
double scale = (1 - hammingDistance / 64) * 100;
return Double.parseDouble(String.format("%.2f", scale));
}
/**
* 获取海明距离
*/
public int getHammingDistance(BigInteger hash1, BigInteger hash2) {
// 求差集
BigInteger subtract = BigInteger.ONE.shiftLeft(this.hashCount).subtract(BigInteger.ONE);
// 求异或
BigInteger xor = hash1.xor(hash2).and(subtract);
int distance = 0;
while (xor.signum() != 0) {
distance += 1;
xor = xor.and(xor.subtract(BigInteger.ONE));
}
return distance;
}
/**
* 获取海明距离
*/
public int getHammingDistance(long hash1, long hash2) {
long xor = hash1 ^ hash2;
int distance = 0;
while (xor != 0) {
distance++;
xor &= xor - 1;
}
return distance;
}
}


本文作者:蒋固金
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!